
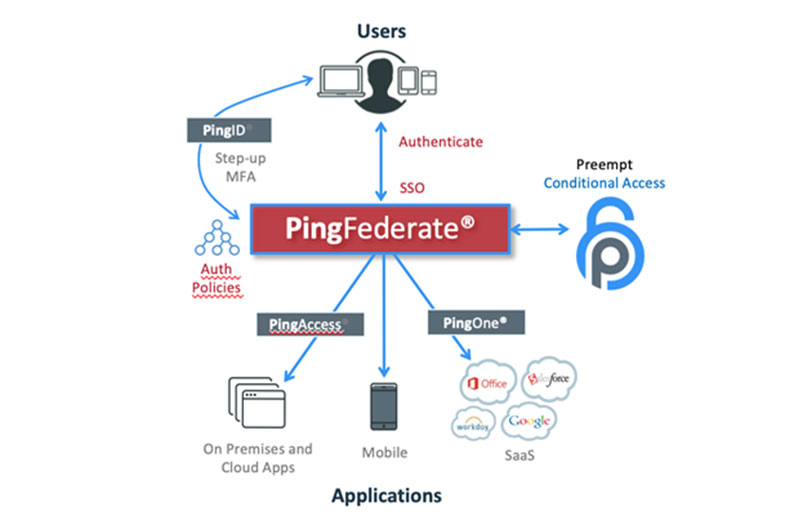
The Preempt Platform extends Ping Federate to any network resource, even access to systems via Remote Desktop Protocol (RDP) without the use of additional agents on the endpoint or target servers. Preempt uses risk modeling of both the user and the behavior via a Machine Learning (ML) model.
This compasses many kinds of data from multiple sources to create a risk score for each user in your identity management system. This risk-based score acts as a gating decision point for step-up identification via Ping, in a way that’s easier for users than a constant or absolute Challenge: Pass or Challenge: Fail.
Let’s review a simple example of user access flow: An employee logs on from a new IP address in abnormal hours using a VPN – does this fact make them malicious? Obviously, without additional data set, it would be hard to decide. It could be an employee on vacation using his personal laptop to review emails. Or it could be malicious actors using stolen credentials obtained in a phishing attack to access the internal network.
To better answer the question, we need to collect context and compare the activity to the user baseline of activity. It is wise to compare this against their peers’ activity and ask do they suddenly behave in a similar manner that can indicate a legit change?
For example, a networking issue. Is it common for this user to travel? Has the user been seen recently from other locations? What is the reputation of the originating IP address and other characteristics of the VPN session (e.g. servers accessed, the volume of outbound traffic) and user (e.g., its business role)?
In many cases, the Security Operations Center or Active Domain analyst reviewing all of these parameters could make a good decision based on their knowledge and prior experience handling security alerts. But this doesn’t scale to a large organization’s needs or traffic.
Preempt uses unsupervised learning to create compound attributes that are used for profiling network users and entities, and to detect malicious activities in the detection engine, all rolled up into a Risk Score. The following are a broad collection of types of data gathered in the neural network, sorted into sources:
Machine Learning User Pattern Data
- Baseline for Entity/User – contains access patterns to services, servers, hours of operations, cloud activity, machine ownership and many other attributes that are used to monitor behavior changes.
- Login history by geographic location
- Login history standard reference baseline – Logged-in hours and days of the week
- User/Endpoint properties – Operating System, risk profile, entity classification (workstation, VDI, etc.)
- User/Entity similarity – Every user has some level of similarity to other members of the domain; Dynamically profiling a narrow peer group allows the system to examine behavior across this comparison group to define confidence levels.
- Contextual Data – concurrent user login, volume of activity in network, etc.
Machine Learning Detection Data
Preempt sifts through all of the collected activities on the network to detect indications of malicious activity. Some of the rules in the detection engine are static and based on known attack patterns and signatures. Obviously, signature-based rules are not sufficient to detect sophisticated attacks, and as a result, Preempt detection engine employs a variety of anomaly detection algorithms. These models run as a tuned ensemble and are able to detect various types of malicious activities such as privilege elevation, lateral movement, geographic anomalies and more.
Machine Learning Entities Data
Entity Classification – Preempt employs an Entities Engine that performs classification of any deployed entity. The Entities Engine uses specially crafted supervised-learning models that are pre-trained by Preempt using large sets of data. These models are used to classify entities. Examples of the entity classifications includes:
- Human vs Programmatic accounts
- Workstation vs Server
- VDI endpoints
Entity classifications are used to create dynamic peer groups that further improve the accuracy of detection engine (e.g. The same activity carried out by an IT admin might be less malicious than the same activity by an executive.)
Collaborative Filtering – Preempt also computes various similarity measures between entities to create dynamic peer groups. For each entity, a multidimensional vector is created which includes IP ranges used by the user, servers they access and a wide variety of other properties. These are then processed using special Matrix Factorization algorithms to create an accurate similarity metric between users.
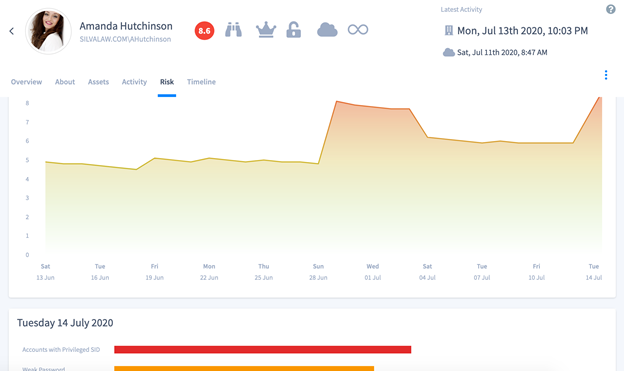
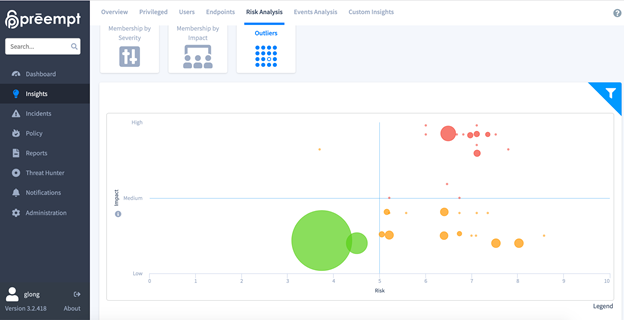
Calculating Risk with Machine Learning
Preempt uses a predictive regression model that factors dozens of traits related to each entity to accurately predict and quantify the vulnerability and threat level for each entity.
This can be visualized in multiple ways via the Interface:
Incorporating User Feedback in Machine Learning
Preempt provides a semi-supervised algorithm that incorporates end-user and security administrator feedback to provide ongoing tuning of the machine learning models. This delivers increasingly accurate detections and classifications that fits the specific behavior of the organization. Here are examples where user feedback is implemented when managing access:
Incidents – Network activity is analyzed via the detection algorithms described above. After reviewing the incident, a security analyst can label it appropriately as a true malicious event or a false positive. Preempt then takes this input into consideration and recalibrates the relevant detection models and algorithms. Exceptions, even complexed, can be made and viewed for each alert type.
Classification – Preempt automatically classifies each entity according to preconfigured heuristics. If a security analyst needs to update a classification or speed up the process with a single operation, they can manually classify an entity or a bulk of entities. This submitted input feeds back into the classification model. Preempt re-learns the classification and applies this new knowledge to other similar entities as they authenticate in Ping.
What the Risk Score does for Conditional Access
Once a user logs into an app through Ping, the login is forwarded to Preempt for evaluation. Preempt evaluates the risk, and returns to Ping if it is allowed, denied, or requires a step up (review) authentication challenge based on user risk factors.The end user input is used to determine the incident severity or even being resolved automatically. In parallel, the Ping authentication result is fed back to the detection engine models making them semi-supervised and more accurate.
Preempt’s risk scoring adds a layer of security and automation to the identity and access management practice. It enhances the Ping MFA suite with actionable data that is easy for users to embrace. The challenges are fewer and password fatigue is lower for everyone.
This because Preempt is monitoring for actions that are anomalies. As an additional benefit, feeding the results of the User –> Challenge –> Success/Fail operations only into a SIEM or SOAR lowers costs. Preempt extends PingID MFA on any network resources, even access to systems via Remote Desktop Protocol (RDP) without the use of additional agents on the endpoint.
Preempt is proud to have Identity and MFA providers like Ping who love to work with us because of the complex and highly accurate way we can represent a risk score for accurate conditional access. And we’re delighted to partner with IDMWorks for their skilled insights and expertise in security integration, helping customers build more secure Identity solutions.