

Another year-end brings another happy holiday blog with tips to help take some of the stress away from having to manage or monitor your IDM system while you’re trying to enjoy some fun, friendly family time.
Last year I talked about how to use driver rules to automatically detect individual transaction successes and errors, and then how to apply that knowledge in other rules for posting data to a system or generating automatic emails to alert someone when there is an issue. And, while that is definitely a handy capability to have in both a holiday season and regular operations, there is still something else that can weigh heavy on an IDM system; driver cache.
In the NetIQ/MicroFocus IDM system, each driver maintains its own cache, or queue if you will, of pending transactions waiting to be processed through that driver’s Subscriber channel. Because drivers will only process one (1) event at a time through a channel, this can create a backlog of events to be processed when dealing with batch jobs, file reads, or other times of heavy interaction. For the most part, drivers can chew through this cache of transactions fairly quickly when one considers that most driver transactions are completed within milliseconds and rarely only a few transactions take more than 1-2 seconds to complete at the most.
However, even at these speeds, it is still possible for data to spool up to be processed. And, at times, due to a variety of reasons, drivers may not be able to process that data as quickly as normal, or even at all. If a remote loader is brought down for any reason, like maybe for patching or a service reboot, then the associated driver for that remote loader will not be able to process data and a queue of events may be formed. Some drivers talk to external connections, like maybe an O365 driver or a SOAP driver. These drivers have to wait for the external, 3rd party application to accept the input and respond with a success/fail message before the driver can move on to the next event. These external responses can take several seconds, even minutes at times, to be returned. Because the driver has to wait to receive that response before moving to the next event, a cache of pending transactions can build for that driver quite easily.
And yes, even though a driver may be working fine today, it does not mean that tomorrow will see the same level of performance. In my experience, I have seen drivers that could process 3,000 new events in less than two (2) hours on one day and the next day it takes twelve (12) hours because of some crazy networking issue, or connected application issue. I’ve even seen issues where an admin might have installed patches on a server but forgot to reboot the server, so the pending patch installations were interfering with the required services until the machine was rebooted.
Often times, as an IDM admin, some of these issues (particularly issues with external applications), may not be communicated to you very quickly (if at all), so unless you have some form of automated monitoring in place for your IDM system, you are unlikely to know that one or more of your IDM drivers are building up caches of events until someone reports a problem that eventually bubbles its way up to you. This can be particularly frustrating or bad during the holidays when fewer people are in the office to address such issues, lines of communication are slower due to reduced numbers of employees during shifts, or even holiday travel where cell phone reception or Internet access may be unreliable or worse, totally unavailable.
So, how can someone relax, and possibly travel, for the holidays without having to worry about driver caches building up without anyone knowing?
Luckily, NetIQ/MicroFocus has thought about this problem for you and has even already integrated a solution into their wonderful IDM product. It is called “Driver Health Configuration.”
In many implementations, this is often an overlooked or under utilized feature of the product. It allows IDM developers and administrators to define a series of conditions to determine a driver’s overall health (green=good, yellow=cautions,red=bad) and each condition can be assigned various actions. This allows each driver to monitor itself using a set of conditions that is specific to that driver and then, if necessary, take specific actions based on what it sees within itself.
This is actually a very clever system that is capable of detecting and responding to a wide variety of things within the IDM environment. However, for today’s post, we are going to focus solely on the driver engine’s ability to monitor its own cache, or queue of events, and send alerts that would be the most likely response in that scenario, especially during a holiday break.
Now, before we dive in, it is important to note that each driver comes with three (3) default states: Green, Yellow, and Red. Each of these states can only contain one (1) rule, unlike normal driver policies that can contain multiple rules. Each state’s rule can have multiple conditions and condition groups, much like a typical driver rule, but, again, only one (1) rule per state.
If someone decides that they need additional rules to check for different conditions or states, then a custom state has to be added to the Driver Health Configuration, but that custom state is still bound by the same one (1) rule limit as the default states. There is no hard and fast limit to the number of custom states that I have experienced, but I would caution that the more monitors you put on a driver, the higher the overhead could be causing some potential for performance loss (so try not to go crazy with multiple custom states unless necessary).
NOTE: These default state rules can be managed in Designer or iManager, which ever you prefer, although it is highly recommended in development practices to always make changes in Designer and then deploy those changes to iManager. For the purpose of this post, I will be using instructions and images from Designer, but know that similar options are available through the iManager UI in the Identity Manager Overview screen for each driver by clicking on the driver’s status icon and selecting Driver Health Configuration from the pop-up menu that appears.
To view/edit a driver’s health settings in Designer, it is as easy as opening the project, right-clicking on the driver, and selecting Properties to open the driver’s property window. In the window, in the left pane, select the option for Health to view the current health configurations for that driver.
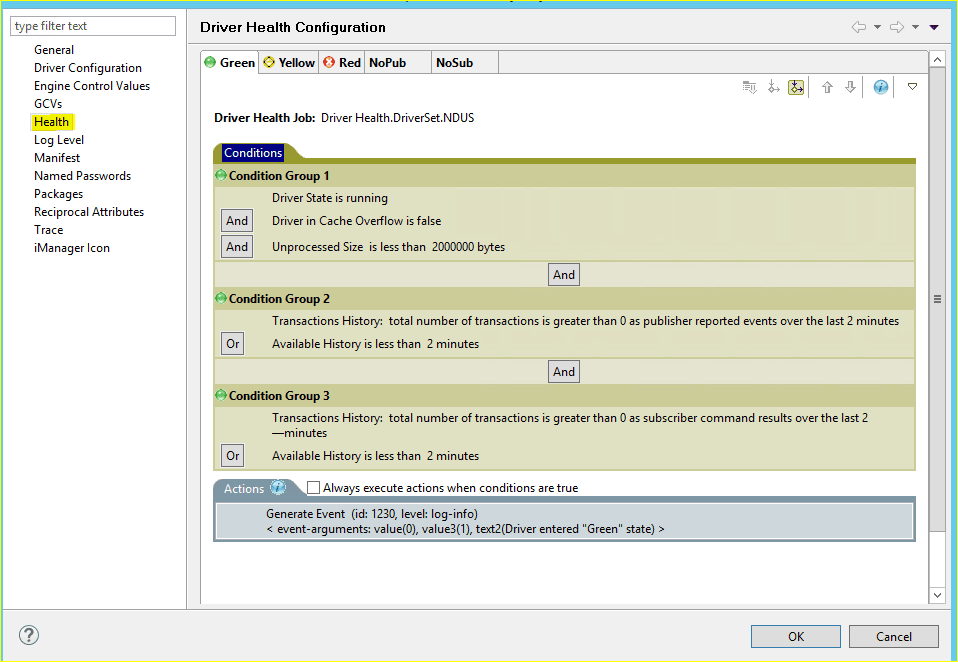
If this is the first time you are accessing this screen for a new driver, you will notice that there are some default conditions and actions for the default states already present. This means that the drivers are already monitoring themselves to a basic extent which can work to serve as a guide or model for tuning these rules to better fit your needs.
Of course, given the choice, I would probably opt to leave the defaults alone and instead create a new custom state where the sole purpose would be to monitor the driver cache. To create a new custom state, click the down arrow on the right-hand side of the menu that appears just below the state tabs and click the option for “New custom state.”

Once a new custom state tab has been added to the window, you are free to define your custom conditions and actions for that state. Defining conditions and actions is very similar to creating a new rule in a policy. Designer will present a series of dropdown menus that will display what options are available based on different selections. Conditions can be coupled together as either an AND or an OR statement. Conditions can be broke apart into multiple condition groups for more complex monitoring logic within a single state’s parameters.
NOTE: The new custom state will have a default name of “custom state” but you can right-click on the custom state tab and choose “Edit” to change the state’s name to whatever you like.
Now, let’s consider that you want to create the custom state to monitor the driver’s cache and sent an email to notify one or more recipients if the cache builds to higher than normal levels or the driver has not processed a transaction for a long period of time.
The following screenshot shows a very basic example of how such conditions could be defined within the state rule.
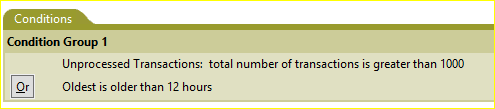
Notice that there are two (2) conditions. The first looks at the total number of unprocessed transactions that are in that driver’s cache (also referred to as a TAO file because the cached data is stored in a .TAO file on the server’s disk). In this example, the rule reads as true if the driver’s cache data shows more than 1,000 events pending for that driver’s Subscriber channel. The second condition does not concern itself with the number of transactions pending but rather the timestamp on the oldest transaction in the cache. If the timestamp, or the time of origin for the original event, is more than 12 hours ago, the rule will be considered true.
Using this example, the state will be true if either condition is met meaning each time the state is checked if the driver’s cache has more than 1000 transactions pending in it OR the oldest transaction in that cache, regardless of the number of transactions, is older than 12 hours. If either condition is true then the state will execute the defined actions.
A state’s actions can include a variety of things including restarting the driver, stopping the driver, sending an email, launching a workflow, or even clearing the driver’s cache! However, in our example, we are more interested in notifying of an issue rather than attempting to self-correct so the following screenshot will focus on the driver’s ability to send an email.
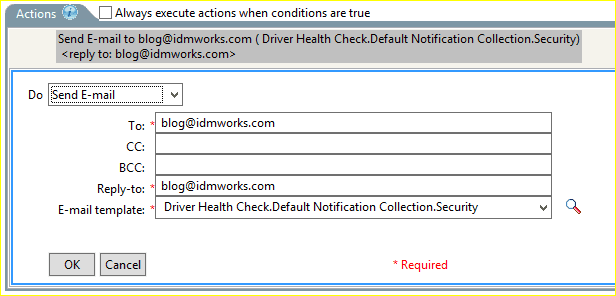
As one might expect, states leverage a very similar method of sending an email to what is seen in standard driver policies. You can define who will be the recipient of the message, any CC or BCC addresses that will also receive of a copy of the email, and you can point to a pre-built email template located in eDirectory. There is even a reply-to address (which is a required field and must have a value).
However, unlike normal driver rules when sending an email, in the driver state actions you are only allowed to use email templates and do NOT have an option to create email messages as part of the state’s actions. Plus, the email templates being used do not have parameters that you can pass or define to give specific custom information in the message. You basically get what you get with the default options which include the driver’s state, the driver’s name, and the server where the driver’s state was reported. These parameters are passed automatically to the email template using the built-in tokens of $HealthState$, $Driver$, and $Server$ so there is no reason for you to define those values as part of the state configuration.
NOTE: If you choose to create a custom email template to be used with this process, the email template is required to have those three tokens available as the driver health functionality does expect them. Templates that do not include those tokens may or may not work as expected with any states attempting to use them.
Another key, and often overlooked, option to a state’s configuration in this screen is the small checkbox next to the Actions tab (see below)

This little insignificant-looking checkbox means the difference between meaningful notifications and a flooded inbox.
Basically, what this checkbox means is that when it is checked, if the rule evaluates to true for any reason, regardless of anything else, that the actions will be applied. Driver health checks happen pretty frequently by default so if this checkbox is true then it could potentially send emails to recipients every few seconds or minutes in this samples’ configuration.
But if you check that checkbox, the health check remembers the health state from the previous check and only executes the state’s actions if the current state is different from the previous state. This means that if the previous health check was true and the current health check is true, i.e. one or more of the conditions were met, then no action is taken because it has already been taken with a previous check. If the previous check was false, i.e. no conditions were met, and the current check was true, the actions will be executed.
By default the checkbox is unchecked and it typically stays that way unless desired.
The last thing to know about using a Driver Health Configuration State is to understand how the IDM engine checks a driver’s health. Health checks are performed automatically by an IDM job that is configured on the driver set, not each individual driver. This is a default job called “Driver Health” that gets installed as part of the IDM engine install. There is no need to create this job because it should exist after the product is installed.
By default, the job is basically always running and polls for new updates every minute. This means that every 60 seconds a command goes out to check every condition for every driver state that is enabled and for states found to be true that those actions are executed when necessary. This goes back to my earlier statement about being cautious when creating new custom states to not create so many custom states that it negatively impacts the performance of your IDM environment.
One final side note before closing this post, the sample state provided here only works for cached events on the Subscriber channel for a driver. Unprocessed events on the Publisher channel would not be available to the driver health check. The Subscriber channel is for processing events that occur within eDirectory out to connected systems which means the drivers running in eDir can be aware of events raised by eDir. The Publisher channel, on the contrary, reads data from a connected system and processes that data into eDir. There is cache, queue, or TAO file for a driver to hold unprocessed events for the Publisher channel because those events are already cached and queued on the target connected system/file. In the event that the driver cannot reach or read data in a connected system then those events will remain unprocessed but to detect that level of connection errors within the driver health would require a different set of conditions. With newer versions of IDM, driver health configurations may also include 2 default custom states for “No pub” and “No sub” which works to verify if the channels are working and communicating with the connected system as expected and takes whatever actions are defined.
Hopefully, this post will help you to enjoy a more relaxing holiday season (and provide benefit throughout the year).
Happy holidays from all of the IAM Pros here at IDMWORKS!