

Linux is, without a doubt, one of the most used server operating systems in the world. It is flexible, powerful, and many times the solutions derived from Linux-based applications are as good as their commercial, and proprietary, counterparts. Linux does have challenges that start from the very moment a user of the host attempts to log in — can the user utilize the same username and password that they use to check their email? How will a range of hosts know what rights a user should have while using them? How will these hosts manage password requirements imposed by the organization? It becomes apparent fairly early on that managing Linux hosts can be a hassle, unless you go in with a sound strategy.
As there is a huge amount of information surrounding these topics, we will break the subject down into multiple posts. In the first installment, we will cover Linux centralized authentication and the key components behind it.
Once we have reviewed how central authentication works, we will be better equipped to talk about an incredibly popular (and well supported) free solution in many distributions, SSSD. We’ll conclude the series by addressing a simple solution for “superuser” access in Linux.
What do we mean by Centralized Authentication?
For the purposes of this blog series, we need a common definition for centralized authentication. Centralized authentication means that a single username and password (i.e. credentials) can be used to access a number of different services because those services all look at the same data set when performing authentication or authorization challenges. This exchange with a centralized authentication source may or may not return a token that can be used in conjunction with a single sign-on (SSO) architecture. Regardless of what mechanisms are used to provide off-network authentication (e.g. cached credentials) or to sustain an SSO session, an initial authentication has to occur somewhere. That somewhere is typically a set of authentication servers that are intentionally in disparate locations.
An Overview of Centralized Authentication in Linux
If you or your organization has ever looked into centralization solutions, it can feel like there are as many solutions to this problem as there are distributions to Linux. Typically, authentication and authorization issues in Linux (at an enterprise-level) are resolved through a basic or centralized model.
Basic Authentication & Authorization flow:
The use case behind basic Linux authentication and authorization is not necessarily difficult.
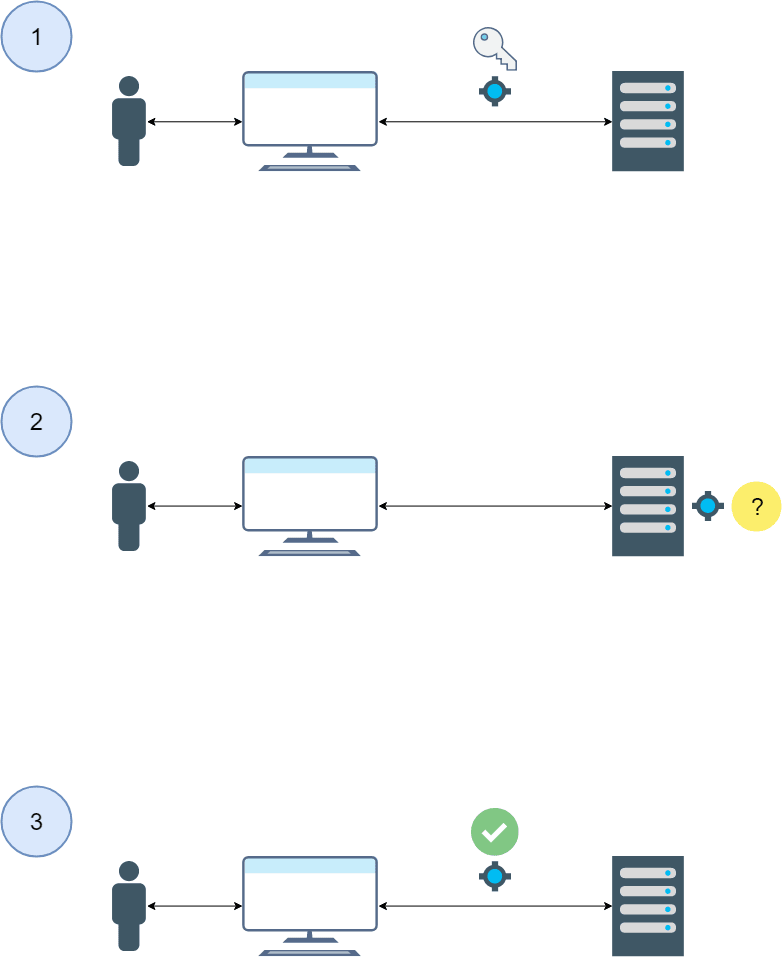
As shown in the diagram above, the basic flow has three major steps:
1) User attempts to access the host and present their credentials – by way of example, let’s assume via Secure Shell (SSH).
2) The user’s credentials are checked against the authentication service.
The “?” above represents the sub-flow as follows:
2A) If the user does not enter sufficient credentials, the session is terminated by the host and access is denied (end flow or repeat step 2).
2B) If the user enters sufficient credentials, but is not authorized to access the host, the session is terminated and access is denied (end flow).
2C) If the user enters sufficient credentials and is authorized to access the host, the user is permitted access (go to step 3).
3) The user is permitted access based on their assigned primary and secondary groups; (e.g. users assigned to a “webserver” group may have access to an Apache webserver home directory but not to directories containing the Splunk agent on the host, per the group assignment).
Centralized Authentication & Authorization flow:
In a centralized model, not much changes in the workflow due to the underlying systems. Instead of the credentials being inquired on the local host, the credentials are inquired at a designated central location on the network.
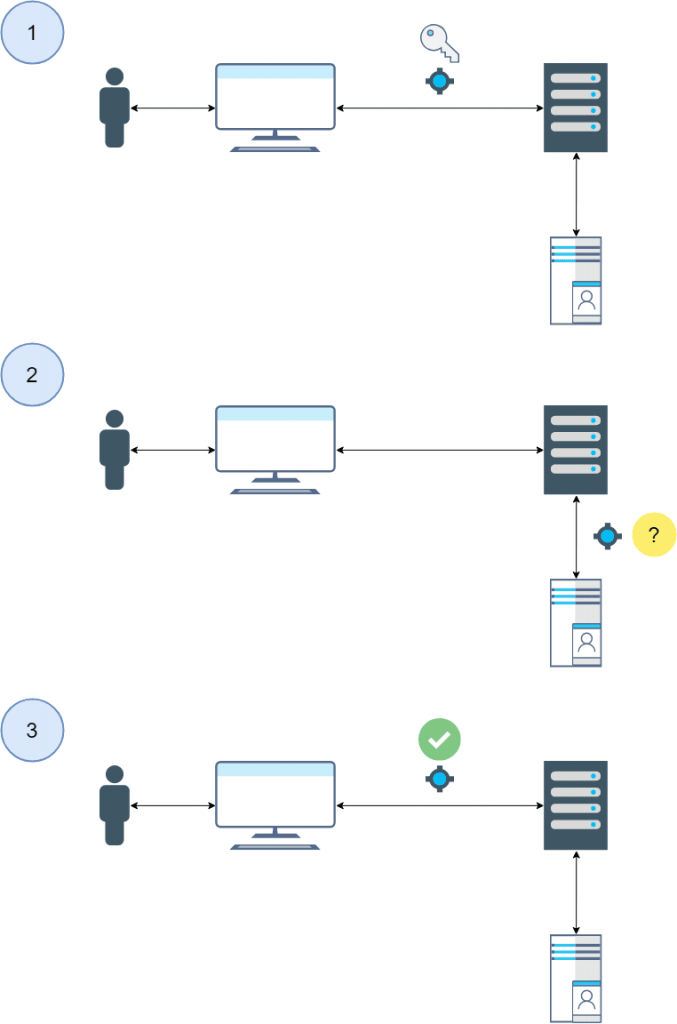
As we can see the flow hasn’t changed significantly, but it bears going back through:
1) User attempts to access the host and present their credentials – by way of example, let’s assume via SSH.
2) The user’s credentials are checked against the remote service. This service will typically contain both authentication data (username, passwords) as well as authorization data (groups and memberships, or attributes used for entitlements).
The “?” above represents the sub-flow as follows:
2A) If the user does not enter sufficient credentials, the remote authentication provider relays that the credentials are bad (typically an LDAP 49 error) to the host. The host denies access based on this piece of information, and access is denied to the user (end flow or repeat step 2).
2B) If the user enters sufficient credentials, but is not authorized to access the host (based on specific membership or attribute criteria), the session is terminated and access is denied (end flow).
2C) If the user enters sufficient credentials and is authorized to access the host, the user is permitted access (go to step 3).
3) The user is permitted access based on their assigned primary and secondary groups, (e.g. users assigned to a “webserver” group may have access to an Apache web server home directory but not to directories containing the Splunk agent on the host, per the group assignment).
There are more advanced use cases in this space (SSH keys, 2FA requirements), but for now, let’s focus on core elements. In a centralized model, when a user accesses a system, they are challenged by the system, that challenge is relayed to another system for inspection and if it is correct, access is allowed.
Almost every solution that works to centralize Linux authentication directly interfaces with a few Linux subsystems. Solution providers such as Centrify and Beyond Trust directly tie into the Pluggable Authentication Modules (PAM) sub-system (the specifics of how it works are too unwieldy for this discussion, however, you can find more information on the TLDP.ORG website). These solutions also tie into something called the Name Switch Service (NSS), which is a list of databases that helps with a wide range of configuration functions in Linux. There are other services that can optionally be tied into for increased functionality (e.g. DNS modifications, SSH modifications), but PAM and NSS are the roots from which their functionality grows.
Why PAM and NSS Matter
PAM allows for the redirection of the Linux authentication flow based on a more standards-driven approach (this is largely due to PAM being well-documented, its source code available for inspection, and deeply integrated with Linux). PAM also allows for modularity; it allows for different services to rely on doing what they do best (e.g. SSH performing its duties) without administrators having to change every service on the host to meet new requirements.
Once a user has been authenticated, the system requires additional information. When specific lookups are performed by applications for additional information (e.g. what groups a user is in), those lookups are referenced against NSS to determine not only where to look, but the order in which to look. An example of this might be checking a password for validity. In that case, the relevant NSS reference might state to look at the local filesystem and only the local filesystem. This “source and priority” lookup method also allows for a degree of modularity as well as a failsafe — if a networked host goes down, break-glass accounts can be maintained to ensure access. More information on NSS (in particular the configuration of NSSwitch.conf, which regulates what gets routed where) can be found in the Linux man documentation.
Where to go From Here
At its most basic, PAM (via LDAP PAM libraries — these are packaged differently based on which distribution they are being used for) can be configured to point to an LDAP server. This LDAP server, in turn, can act as the centralized authentication source. The NSS can be configured to look at an LDAP system first and then locally to determine if A.) The user exists, B.) A user is legitimate based on credentials, and C.) The user is authorized to access what they are trying to access. This implementation, though simple in its setup has been a part of Linux since at least the early 2000s (with the initial implementation being performed by PADL) and thus widely available. It is also an extremely lightweight approach to getting a Linux host to communicate with a centralized source of authentication data.
This implementation suffers from distinct disadvantages, the foremost of which being that PAM LDAP does not have an easy way of knowing when a server goes down or remains down. What this means is that generally a single “target” for authentication (such as a load-balanced LDAP system) needs to be used. Along the lines of system status, when the LDAP target is down no authentication or authorization can be performed (unless it’s local). While this is a flaw of all centralized mechanisms, there are design decisions that can mitigate this (to be covered in a future blog).
This enables, at a high level, some really exciting capabilities:
1.) Centralized authentication to a properly configured host
2.) Increased auditability of all hosts that rely on the centralized solution
3.) The ability to tune Security Information & Event Management (SIEM) to alert on “local” host authentication, which could be indicative of break-glass scenarios or attacks
Coming up Next
Now that we have a basic grasp on what centralized authentication is, our next step in the discussion is to look at one such (Free!) solution in earnest.
A final note, icons used in the above diagrams can be found at the Draw.io Github repository.